Audiorium: ML Music Recommendation
Description
Audiorium
Cultivating Diversity in Music Recommendation with Latent Representations of Audio
A next-generation, culturally inclusive music recommendation system that surfaces music based on meaning — not popularity, streams, or label affiliation.
Author: Anish Ghosh (axg1652@miami.edu)
Collaborator: Yestin Arvin Gochuico
Affiliation: Department of Music Engineering & Department of Interactive Media, University of Miami
Course: Design with AI — Fall 2025
Table of Contents
- Introduction
- The Problem
- Dataset
- Methods
- System Architecture
- User Interface
- Related Work
- Evaluation
- Future Work
- Setup & Usage
- References
Introduction
Audiorium is named after a fusion of audio + museum / terrarium / aquarium — a space where users cultivate their own ecosystem of music. The application was built around one core idea: music recommendation should be driven by sonic and semantic meaning, not by engagement metrics, streaming counts, or label affiliation.
Research Question:
How can machine learning be utilized to develop a music recommendation algorithm that works beyond searching?
Target users: Music lovers who want to go beyond the mainstream and genuinely diversify what they listen to.
The Problem
With the emergence of music streaming, recommendation algorithms have become a primary force in culture curation and global discovery. Current platforms suffer from two compounding issues:
- Feature Translation Gap: Audio features used in mainstream algorithms struggle to translate inclusively across genres and cultures.
- Recommendation Homogenization: Algorithmic optimization for engagement creates echo chambers of western pop dominance — rewarding the familiar and profitable rather than delivering transformative experiences.
Dataset
Free Music Archive (FMA) Small Dataset — the standard benchmark for genre classification and audio feature extraction.
| Property | Detail |
|---|---|
| Genre coverage | 161 genres, from broad (Rock) to niche (Glitch) |
| Dataset sizes | Small (8k tracks) → Full (106k tracks) |
| Precomputed features | MFCCs, Chroma, and more |
| License | Creative Commons — open for raw audio research |
Methods
Audiorium combines three complementary AI capabilities:
| Capability | Model | Description |
|---|---|---|
| Text-to-Audio Search | CLAP | Natural language queries mapped to audio embeddings |
| Audio-to-Audio KNN | CLAP | Find tracks with similar sonic principal components |
| Image-to-Audio | OpenCLIP | Visual context mapped to audio via shared latent space |
Additional design decisions:
- Inspired by Spotify’s Text2Track and MusicMakerHub
- Rule-Based Ordering adds slight randomization to top results, ensuring equitable distribution of diverse content over pure similarity ranking
System Architecture
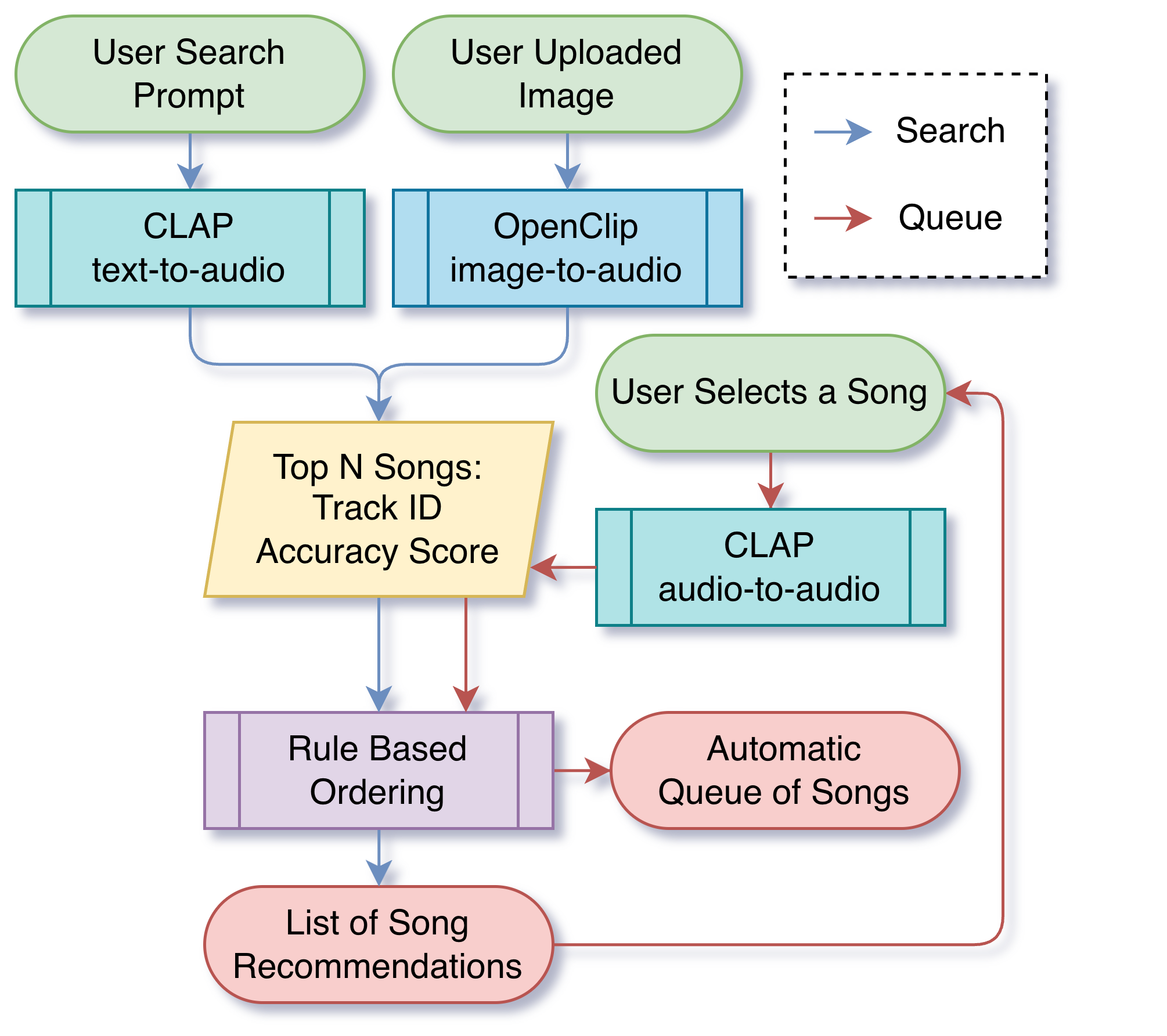
The system runs two parallel pipelines:
Search pipeline (text or image input):
User Prompt / Photo → CLAP text-to-audio / OpenCLIP image-to-audio
→ Top N Songs (Track ID + Accuracy Score)
→ Rule-Based Ordering
→ Recommendation Songs & Artist
Queue pipeline (song selection):
User Selects a Song → CLAP audio-to-audio KNN
→ Top N Songs (Track ID + Accuracy Score)
→ Rule-Based Ordering
→ Automatic Queue of Songs
FAISS Index: All audio is pre-embedded using CLAP and stored in a FAISS IndexFlatIP (cosine similarity via L2-normalized inner product) for fast nearest-neighbor retrieval at scale.
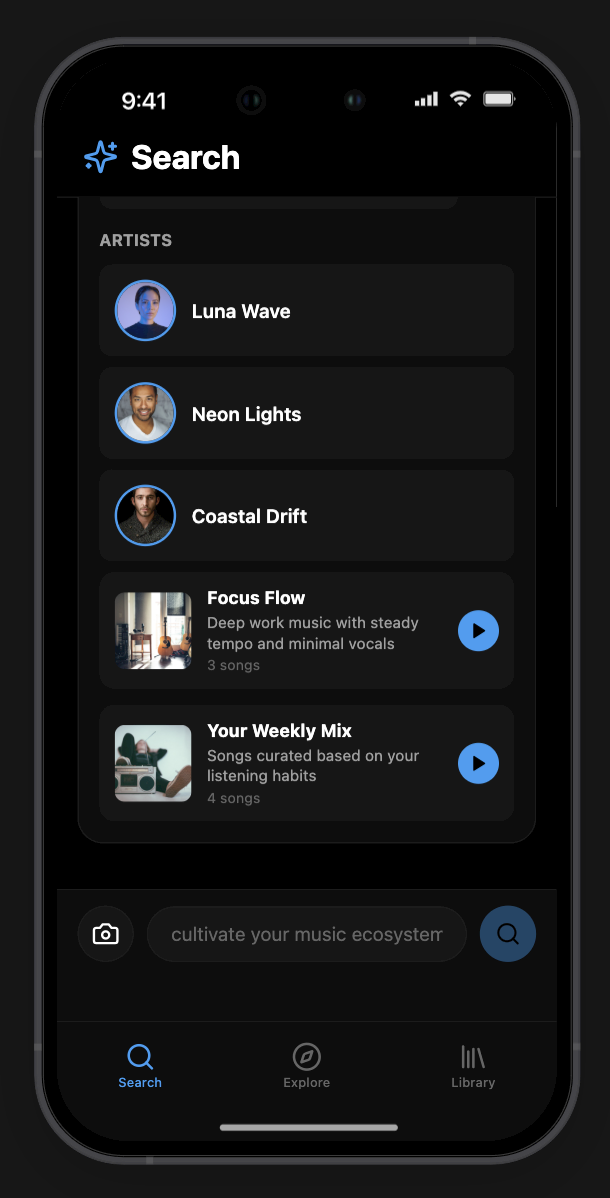
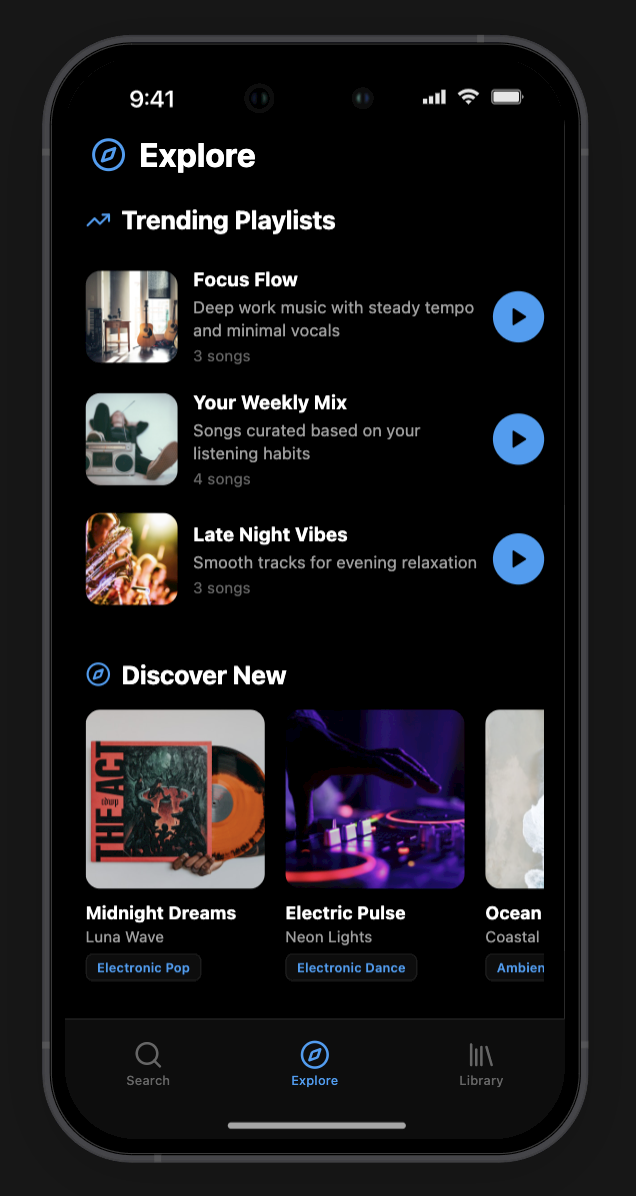
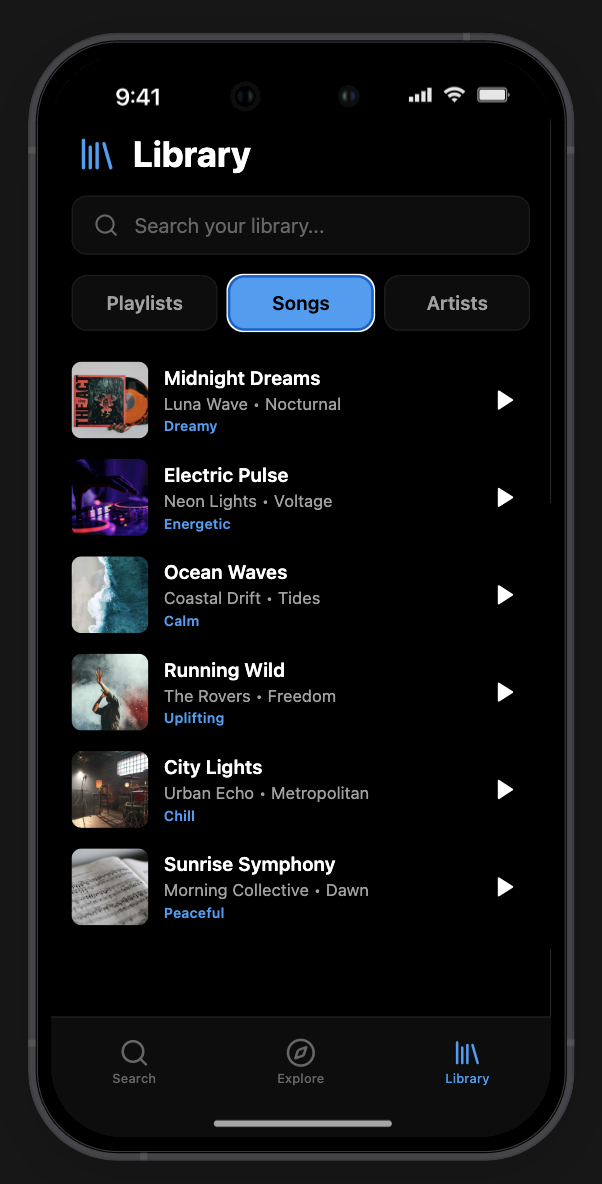
User Interface
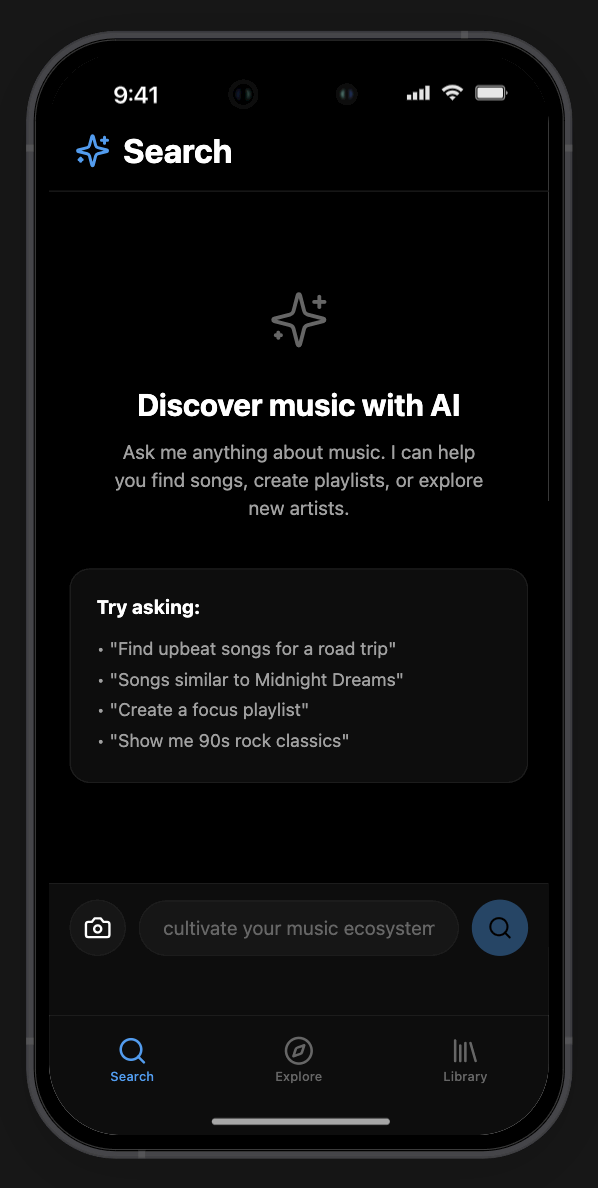
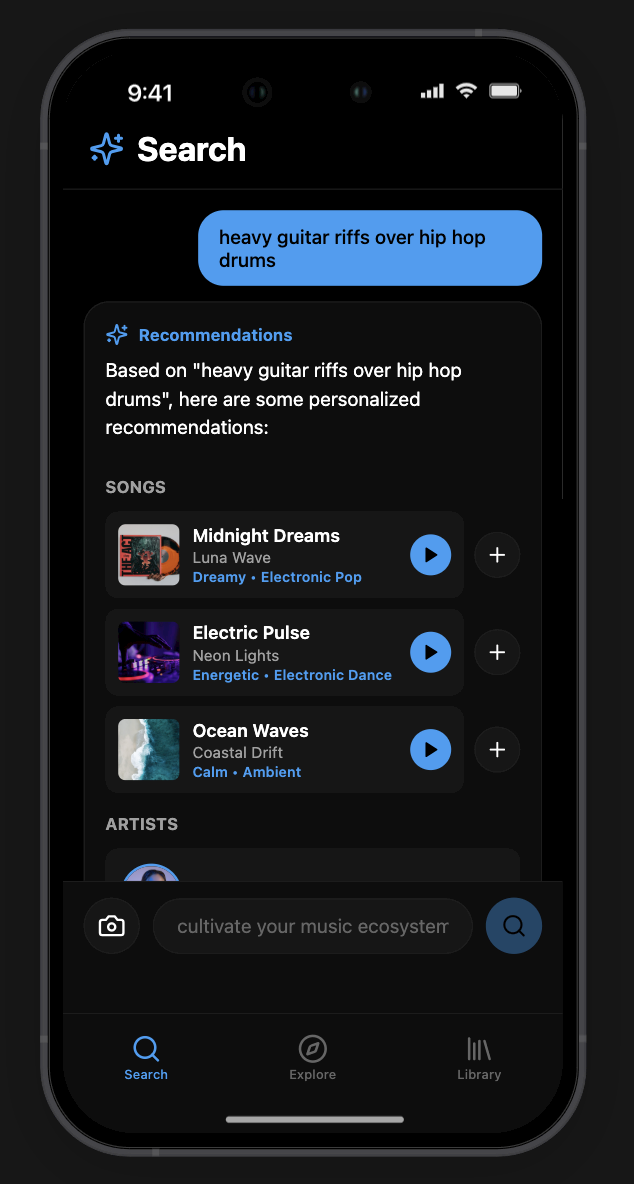
The GUI is a hybrid of a text-bar interface (like ChatGPT) and a standard media player (like Spotify). Prototyped in Rork, a Lovable/Cursor-based AI app prototyping tool using JSON prompting.
Interface elements:
- Central search bar for natural language queries
- Photo upload / camera access directly from the search bar (multimodal input)
- Results (playlists, artists) surface dynamically above the input
- Sidebar: search history, playlists, user library
- Conceptual 3D universe / neural map of music for visual discovery
Changes from initial proposal:
- Geolocation (Pokémon GO-style music discovery) was cut from scope
- Image-to-Audio input was added to make the experience more interactive
Screenshots
| Search | Results | Artists |
|---|---|---|
 |
 |
 |
| Explore | Library |
|---|---|
 |
 |
Related Work
| Project | Description |
|---|---|
| Musixmatch Music Lens | AI agent for music discovery |
| Music Atlas | Discovery and geographic visualization tool |
| Magenta SpaceDJ | AI-powered DJ / music tool |
| Liu et al. — CLAP (2023) | Core reference: AI-assisted sound searching via contrastive language-audio pretraining |
| Liu (2024) — CLAPSearch | Search interface built on CLAP latent space |
| Text2Tracks (Spotify Research) | Prompt-based music recommendations with generative retrieval |
| How Bad Is Your Streaming Music? | Spotify API + AI storytelling / taste critique |
Evaluation
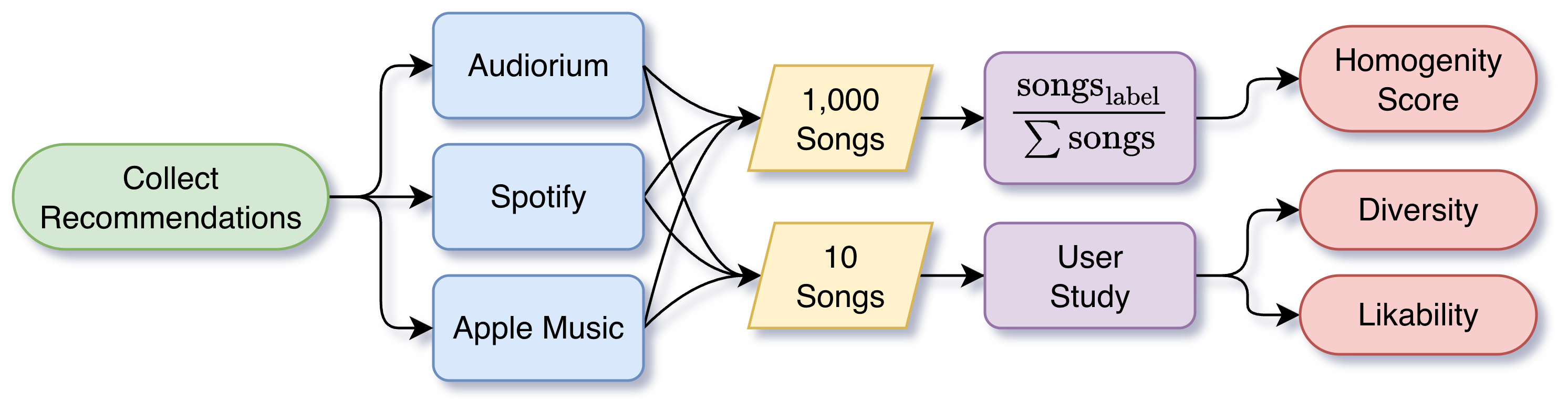
Methodology
Recommendations were collected from Audiorium, Spotify, and Apple Music, then evaluated across two dimensions — algorithmic (1,000 songs) and via user study (10 songs).
Quantitative: Homogeneity Score
Measures the proportion of major-label artists in the top-100 recommendations (0 = fully independent, 1 = all major label). The population baseline — the real-world ratio of label to non-label music — is 0.3, making that the ideal target score.
| Audiorium | Spotify | Apple Music | |
|---|---|---|---|
| Homogeneity Score | 0.28 | 0.61 | 0.83 |
Table 1: Homogeneity scores for 1,000 recommended songs per algorithm
Audiorium’s score of 0.28 is the closest to the 0.3 target, confirming the algorithm is effectively label-blind and does not reward streaming popularity or label affiliation.
Qualitative: User Study (Likert 1–5)
Participants listened to recommendations from each platform and rated them on diversity and likability.
| Measure | Audiorium | Spotify | Apple Music |
|---|---|---|---|
| Diversity | 3.62 | 2.21 | 1.35 |
| Likability | 1.49 | 3.25 | 2.51 |
Table 2: Likert scale means for user perception of diversity and likability
Audiorium achieved the highest diversity score by a significant margin. The lower likability score is attributed to a known confounding variable: Audiorium’s recommendations come from an open-source dataset, while Spotify and Apple Music surface commercially released and professionally produced music that participants are more predisposed to enjoy.
Future Work
- Retrain on the Free Music Archive Large Dataset (106k tracks) for broader coverage
- Longitudinal studies comparing commercial algorithms to Audiorium over days to weeks of real use
- Quantify the performance of the image-to-audio recommendation capability independently
- Explore integration with real-world music catalogs to reduce the open-source dataset confound in likability evaluation
Setup & Usage
Requirements
pip install torch torchaudio transformers faiss-cpu spotipy librosa soundfile requests
Also requires ffmpeg:
brew install ffmpeg
Run
python audiorium.py
On first run, the script embeds all audio in mp3dataset/ and saves a FAISS index (clap_music_index.faiss) and track ID list (ids.pkl) to disk. Subsequent runs load the index instantly — no re-embedding needed.
Query Examples
# Text-to-audio search
recommend_by_text(\"chill lo-fi with piano and rain\")
recommend_by_text(\"aggressive 808 trap with dark strings\")
# Audio-to-audio similarity
recommend_by_audio(\"mp3dataset/Plain.mp3\")
Project Structure
Audiorium/
├── assets/
│ ├── audioriumflow.png # System architecture diagram
│ ├── audieval.png # Evaluation methodology diagram
│ └── poster.pdf # Academic poster (University of Miami, 2026)
├── mp3dataset/ # Local audio library (gitignored)
├── audiorium.py # Core recommendation engine
├── Audiorium.ipynb # Original Colab notebook
└── README.md
References
- Anderson, A., Maystre, L., Anderson, I., Mehrotra, R., & Lalmas, M. (2020). Algorithmic effects on the diversity of consumption on Spotify. Proceedings of The Web Conference 2020, 2155–2165.
- Born, G., & Diaz, F. (2021). Artificial intelligence, music recommendation, and the curation of culture: A white paper. Schwartz Reisman Institute for Technology and Society, University of Toronto.
- Defferrard, M., Benzi, K., Vandergheynst, P., & Bresson, X. (2017). FMA: A dataset for music analysis. Proceedings of ISMIR 2017, 316–323.
- Liu, H. (2023). AI-assisted sound searching based on contrastive language-audio pretraining (CLAP).
- Liu, H. (2024). Learning audio patterns with latent diffusion models and contrastive learning [Doctoral dissertation, University of Surrey].
- Schedl, M., Zamani, H., Chen, C. W., Deldjoo, Y., & Elahi, M. (2018). Current challenges and visions in music recommender systems research. International Journal of Multimedia Information Retrieval, 7(2), 95–116.
- Sturm, B. L. (2014). A simple method to determine if a music information retrieval system is a "horse." IEEE Transactions on Multimedia, 16(6), 1636–1644.
- Zhu, P., Pang, R., Jiao, Y., & Tang, K. (2023). Text2Track: Text-to-Track generation with high-fidelity and structural consistency. Proceedings of the 31st ACM International Conference on Multimedia.”